Continually Adapting Speech Recognition Models
This was my research project with the Spoken Language Systems group at MIT CSAIL during Research Science Institute 2009, which I entered in various high school science competitions.
Advances in automatic speech understanding bring a new paradigm of natural interaction with computers. The “Web-Accessible Multi-Modal Interface” (WAMI) system, developed at MIT’s CSAIL, provides a speech recognition service to a range of lightweight applications for Web browsers and cell phones.
In this research I addressed two limitations in the WAMI system. First, to improve performance, it required continual human intervention through expert tuning—an impractical endeavor for a large shared speech recognition system serving many applications. Second, WAMI was limited by its global set of models, suboptimal for its unrelated applications.
I developed a method to automatically adapt acoustic models and improve performance. At the same time, I extended the WAMI system to create separate models for each application. The system can now adapt to domain-specific features such as specific vocabularies, user demographics, and recording conditions. It also allows recognition domains to be defined based on any criteria, including gender, age group, or geographic location.
These improvements to WAMI bring it one step closer towards being an “organic,” automatically-learning system.
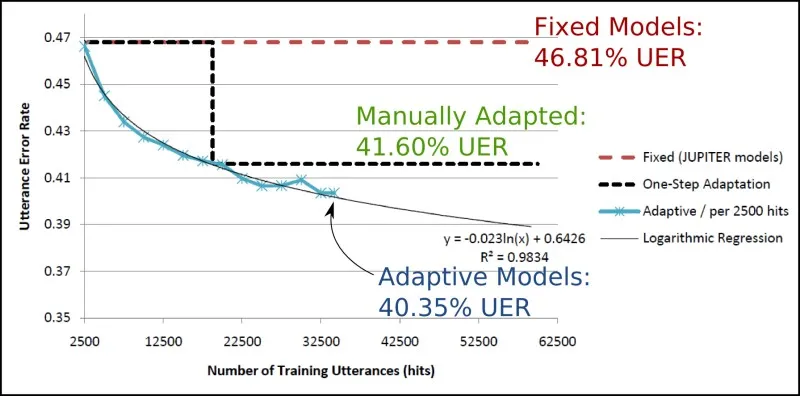
Improving performance of the speech recognizer with adaptation